HasMySecretLeaked - Building a Trustless and Secure Protocol
We can’t see your secrets, but we can tell you if they’ve leaked on GitHub. Here’s how we do it.

HasMySecretLeaked is the first free service that allows security practitioners to proactively verify if their secrets have leaked on GitHub.com. With access to GitGuardian's extensive database of over 20 million records of detected leaked secrets, including their locations on GitHub, users can easily query and protect their sensitive information. This database is compiled from scanning billions of code files, commits, GitHub gists, and issues since 2017.
By opening this project to everyone, we strive to enhance secrets protection at scale while acknowledging the responsibility and security challenges involved.
At GitGuardian, we believe in transparent, accessible and understandable security. This is why we aim to uphold complete transparency regarding the protocols behind HasMySecretLeaked. Our goal is to ensure the service remains resilient against malicious misuse while also fostering a trustless environment: with HasMySecretLeaked, you can rest assured that your secrets are secure - at no point do we have access to them, so you don’t even need to trust us!
To support these claims, this blog post dives into the technical choices that went into creating a safe yet pragmatic and easy-to-use protocol. Without further ado, let’s get started.
How We Built the Protocol
HasMySecretLeaked is a highly efficient REST API designed to take a string of characters as input. Its key function is to answer with 100% assurance the critical question - 'Has my secret leaked?'
Here is an example request for the fffff input to show you what a typical response looks like:
$ curl https://api.hasmysecretleaked.com/v1/prefix/fffff
For this input, the HasMySecretLeaked API response's payload is:
"matches": [
{
"hint": "0ea3b034632487a17ba18e7086156c14cc8eb9993e33aec8e348183044b299b1",
"payload": "adO72+jWqHstJso2DacOj..."
},
{
"hint": "ddf4ef722ca2ec541074811692eff789bf48d963fa28e42d5542edc8e887239c",
"payload": "sHrlooMIShmf+Oh0yqcYm..."
},
...
As you can notice, there is more going on under the hood. To understand how the client uses this information and the API design decisions involved, let's start from scratch with a naive, insecure, protocol implementation and iterate from there.
1. Naive approach
In the most straightforward approach, the user would send their secret directly to the API. Problem: the service, aka GitGuardian, would "see" the users' secrets in cleartext, which is unacceptable.
So, how can a user know whether their secret is in our database of leaked credentials without sharing their secret with us?
Response: using a hashed version of the secret.
2. Hash-based approach
Now, let’s imagine the user sends a hashed version of their secret to the API. This is definitely an improvement, as the secret is obfuscated, and the service cannot reverse the hash. There is still a privacy problem, though: by definition, if the hashed secret is present in our database, it implies that its cleartext version was once publicly accessible, indicating that GitGuardian has or had knowledge of it. In other words, the user would be leaking their secret to us. And that’s not acceptable either.
So, how can we prove GitGuardian has zero-knowledge about the requested secret?
Response: by responding with multiple possibilities.
3. Bucket-based approach
In this approach, the user only sends a fragment of their secret's hash - specifically, the initial 5 characters. The service then retrieves all secrets it holds that align with these five characters. By ensuring the response 'bucket' is sufficiently large, we effectively veil the original secret request from the service, maintaining the user's privacy.
💡The bucket's size is intrinsically linked to the hash chunk's length: a longer string yields a smaller bucket. Through hands-on experimentation, we've found that a five-character size currently delivers optimal results. However, this is not set in stone and may be fine-tuned in the future.
👍 A hearty acknowledgment to Troy Hunt's HaveIBeenPwned, which significantly inspired this design!
Now, we have a secure service, yet it's missing a crucial feature. For the service to prove its claim that the secret has been leaked, it must provide the URL location of that leak. Without this feature, the service's usefulness would be almost null.
So, how can we share the URL of the leak while maintaining the confidentiality of the remaining URLs in the bucket?
Response: by encrypting this information so only the secret's owner can retrieve it.
4. Adding encryption
The idea is simple: each element in the response bucket is now encrypted (using AES-GCM) with the (full-length) hash of the secret as the key. This way, we can guarantee only a user knowing the hash (and therefore the secret) will be able to decrypt the payload and retrieve the URL location.
This additional layer of encryption significantly reduces the risk of an enumeration attack. Without it, a cybercriminal could potentially attempt every five-character combination, thereby harvesting our entire database of hashed secrets. However, there remains another potential attack scenario that we'll be addressing shortly.
We are now faced with a usability issue: the client must painstakingly decipher each item individually to potentially locate the one they possess the key for. There is no way to quickly get an answer to the crucial question: has my secret leaked?
So, how can we allow the client to get an answer quicker?
Response: by providing an easy-to-check hint for each match.
5. Providing a hint
The API now provides encrypted responses, coupled with a unique feature - a hint, essentially a hash of the hash. This allows the client to swiftly calculate the hint and determine if a match exists within the response. Put simply, they can rapidly confirm if the hash of their secret is present in the database. To dig deeper, they only need to decrypt the specific item using the original hash of their secret.
We’ve now built a robust service, which corresponds to the example structure presented at the beginning of this article. Let's address the attack scenario mentioned before.
6. Preventing other risk scenarios
a. An attacker compromises a similar database
This scenario implies that an attacker manages to compromise a database of hashed secrets using the same hash function as the one used by our service. In that very special case, they could use our service to reverse the hashes, collect all the locations, and uncover the cleartext secrets.
To mitigate the above threat, we added a pepper to our hashing function.
A "pepper" is an additional string added into the hashing process to further increase security. Unlike a "salt", which is unique for each item, a "pepper" is global.
Adding a pepper makes our hashing function unique and mitigates the possibility of an attacker reversing our hashes with a dumped database.
b. An attacker uses a "rainbow table"
What happens if someone attempts to guess the secrets? Similar to passwords, many secrets are not randomly generated but hastily created. This makes them vulnerable to attackers who may use a "rainbow table" - a precomputed table for reversing cryptographic hash functions - to probe our service with a list of common combinations in an attempt to uncover any leaks.
To mitigate this risk, we've implemented two safeguards:
The service only discloses the first location where a secret is found. This strategy restricts the amount of information that can be misused without hindering legitimate usage.
Unauthenticated users are limited to five service queries per day. This IP-based rate limit creates a barrier for anyone hoping to strike it lucky with random attempts (we also rate limit authenticated users, but it is less stringent).
7. Wrapping up: final design implementation
Here is the final interaction diagram to summarize what happens client-side and server-side:
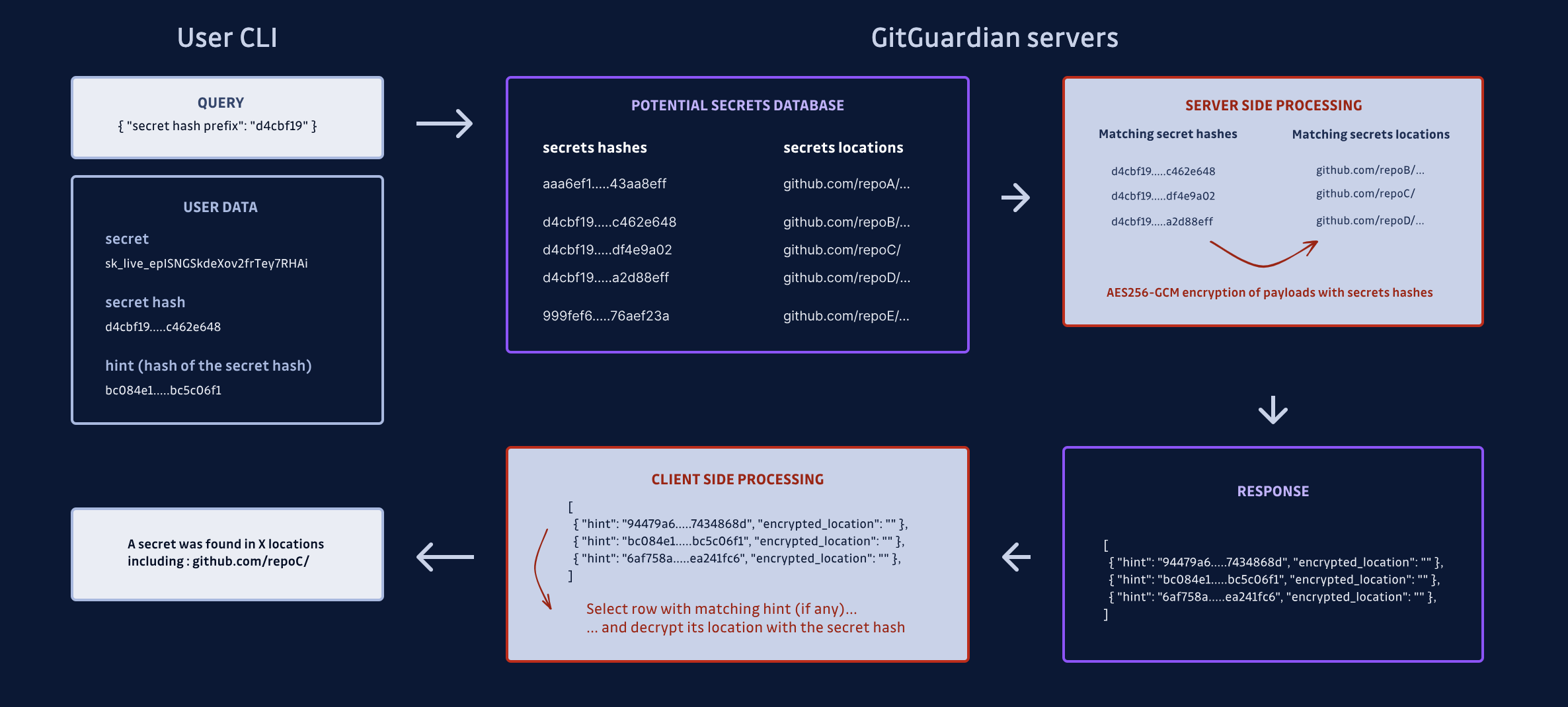
HasMySecretLeaked protocol
Two interfaces implement the client-side protocol we described here to interact with the service API:
the Javascript code your browser downloads when visiting HasMySecretLeaked
the GitGuardian CLI
ggshield, with the new optionggshield hmsl
This is the end of our journey! To wrap up, here are the key takeaways you need to remember about HasMySecretLeaked:
At no point does GitGuardian have access to your secret.
We fully recognize the immense responsibility associated with managing sensitive data, and we take the security challenges seriously.
Your secret is obfuscated client-side and cannot be reversed by our services.
Your secret request remains private because you only send the initial five characters of the hash.
If we find a hit, only you, as the owner of the secret, can decrypt the payload and retrieve the URL location.
We have ensured that checking if your secret is included in the response is quick and simple without compromising privacy.
To reduce potential risks, we have added extra security measures to our system, such as making our hashing function more complex and restricting the number of service queries allowed per day.
We hope you are now ready to take HasMySecretLeaked for a spin with the peace of mind knowing your secrets are safe!
Get started with HasMySecretLeaked
Addendum: Deep dive into technical choices
Prefix size
As said earlier, it is important that users share only the prefix of their hashed secret with us, and it is as important for GitGuardian to design the service so that buckets are big enough. This approach ensures that GitGuardian retains minimal, if any, knowledge of the user’s secret.
The challenge here lies in striking a balance: if the buckets are too small, GitGuardian inadvertently gains excessive insight into the user’s secret. Conversely, overly large buckets can burden the API with hefty payloads. To determine the ideal prefix size, we need to estimate the potential number of secrets in our database.
Currently, our HMSL database houses approximately 22 million unique secrets. We've selected a prefix composed of 5 hexadecimal characters, yielding roughly 1 million buckets and an average of about 22 secrets per bucket. Assuming that the hash distribution is random and follows a normal distribution, we've ensured no bucket contains fewer than 8 secrets, which aligns with our protocol.
It's important to note that as more secrets are leaked over time, the buckets will gradually fill up. If they become too cumbersome for our API, we can simply extend the prefix length by one, effectively reducing the average bucket size by a factor of 16.
Hashing function
Our chosen hashing function must adhere to the canonical properties of a hashing function, primarily to deter users from reversing a hash and, consequently, extracting passwords from our database. However, there's an additional complexity to consider. Passwords don't follow a random distribution; in fact, they're quite predictable. Passwords can be systematically enumerated, beginning with the most common ones.
If an individual knows the prefix of a user's hash, they could swiftly compute hashes from a standard list of passwords and compare them to the prefix. If they stumble upon a match, they can reasonably conclude that they've cracked the user's password.
To counter this, we need to select a hashing method that strikes a balance between speed and complexity. It must be quick enough to ensure a smooth user experience yet intricate enough to thwart attackers from rapidly generating a vast list of hashes. This led us to select scrypt as our preferred hashing method.




